

A few days ago DeepSeek released R1, an open source reasoning model similar to OpenAI’s o1. The model quickly became the center of tech twitter discourse - for good reason. Users report it as comparable in performance to OpenAI o1, making it the first open-weight model to be on par with state-of-the-art closed ones.
At Greptile we build AI tools that find bugs in pull requests. In production we use a variety of models including o1, Claude 3.5 Sonnet, and GPT 4o. Naturally, an open source SOTA model is compelling for us, especially because it lets us deploy models to our customers’ cloud, adding a layer of security without compromising performance.
Benchmarks
While there isn’t a good pull request review benchmark, DeepSeek claims that R1 beats o1 on SWE-bench, a popular benchmark that tests models’ abilities to generate functioning PRs from real-world GitHub Issues.

TechCrunch DeepSeek R1 claims to beat OpenAI o1 on SWE-bench
In my experience, SWE-bench performance does not translate well to PR review performance. In fact, most of our colleagues that build agents for specific verticals say that performance on popular benchmarks don’t tend to correlate too strongly with real-world performance on the margins.
Reviewing PRs with DeepSeek
I decided to test DeepSeek R1 by having it review real world PRs and surface bugs/issues. To make the test fair, I removed all of the scaffolding that our product has - prompts, agents, RAG, etc. This is because a lot of our scaffolding is optimized for the idiosyncrasies of our current set of models.
This is a crude diagram of the scaffolding we have:
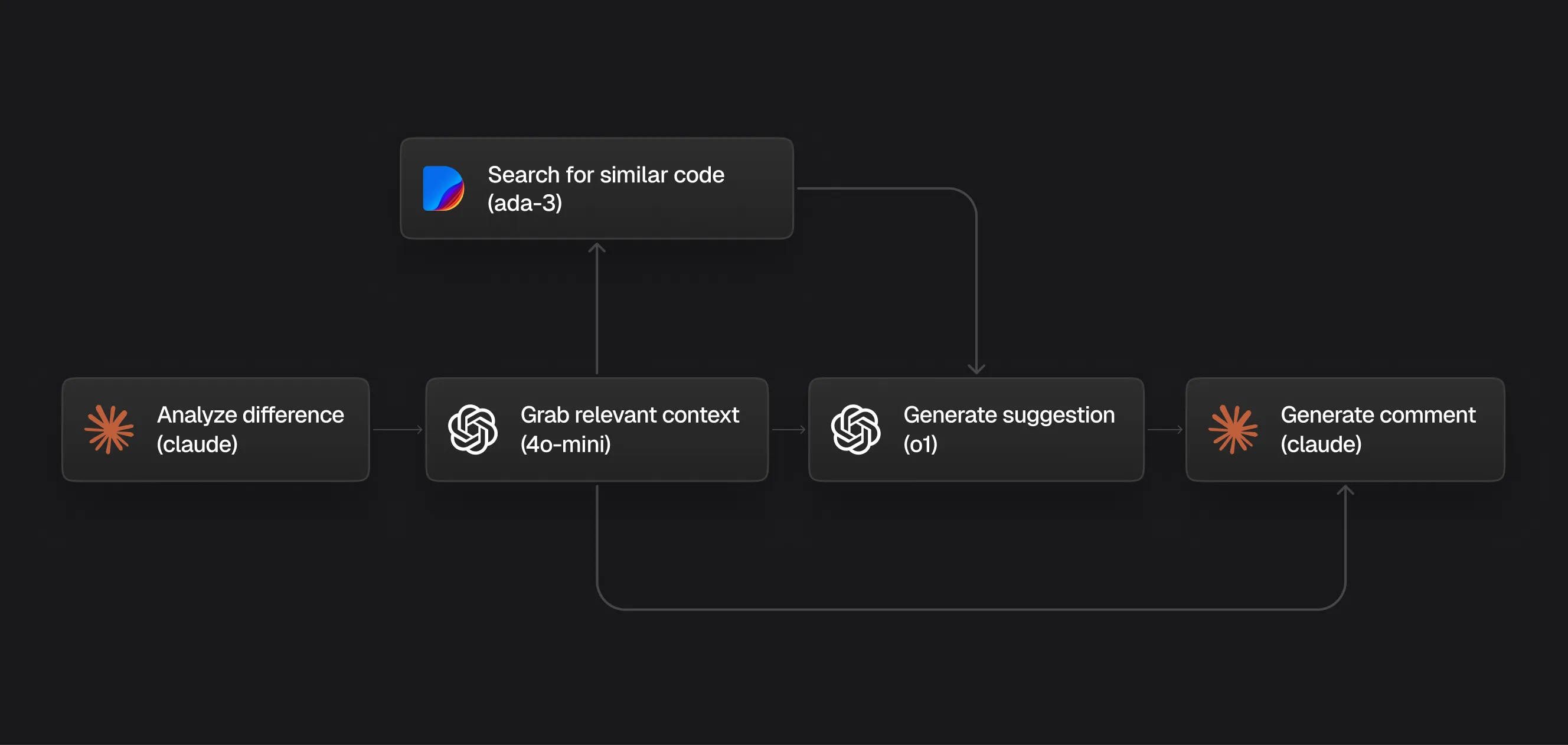
Diagram showing Greptile scaffolding for PR review
I disposed of it all and used a simple prompt:
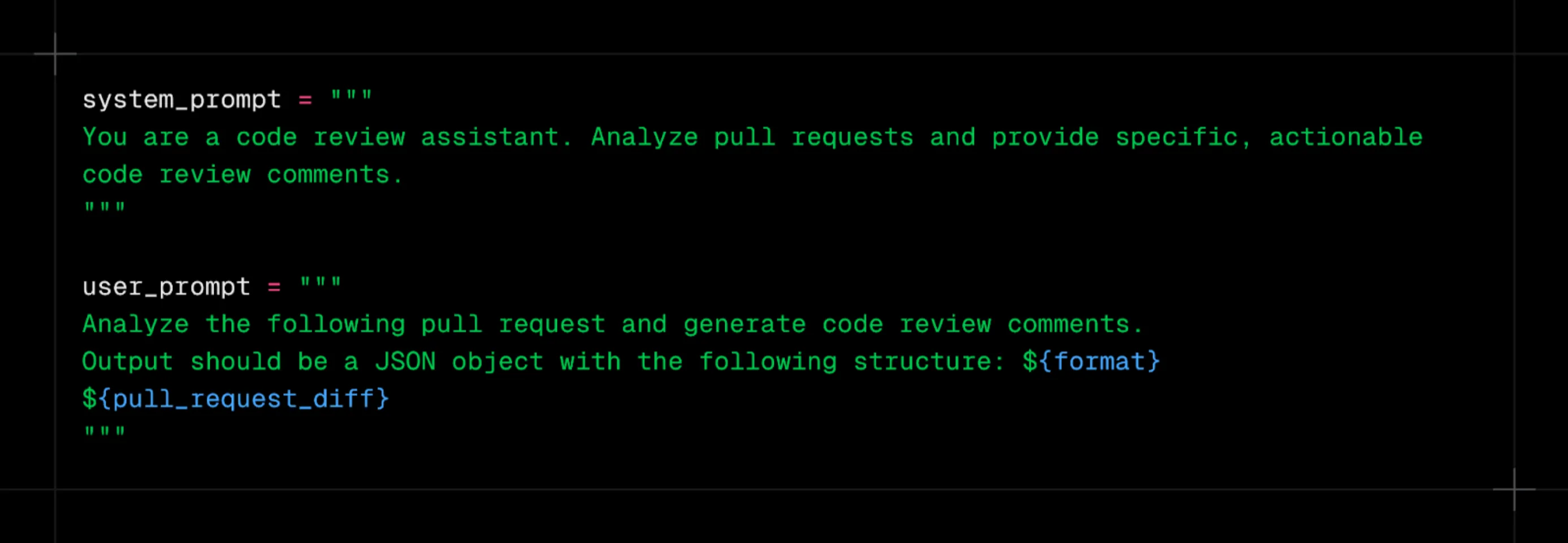
Simple prompt used to test DeepSeek R1 and OpenAI o1
In essence, the test here is to detect the bugs/antipatterns that are hidden in the diffs. I ran the bot on 15 PRs. I purposely selected PRs where the bug or antipattern is completely detectable by looking only at the diff, with no additional context required from other parts of the codebase. Each PR has an exhaustive set of good comments.
To my surprise, DeepSeek vastly outperformed o1 on this task. I was both surprised by how well it performed and also how badly o1 failed.
I didn’t want to include all 15 PRs here, so I picked three at three different levels of complexity to let you compare.
Pull Request 1:
This pull request was made on a large crypto project’s repo. There were three things that the models should have surfaced: a naming problem, a potential race condition, and a missing entry in an array.
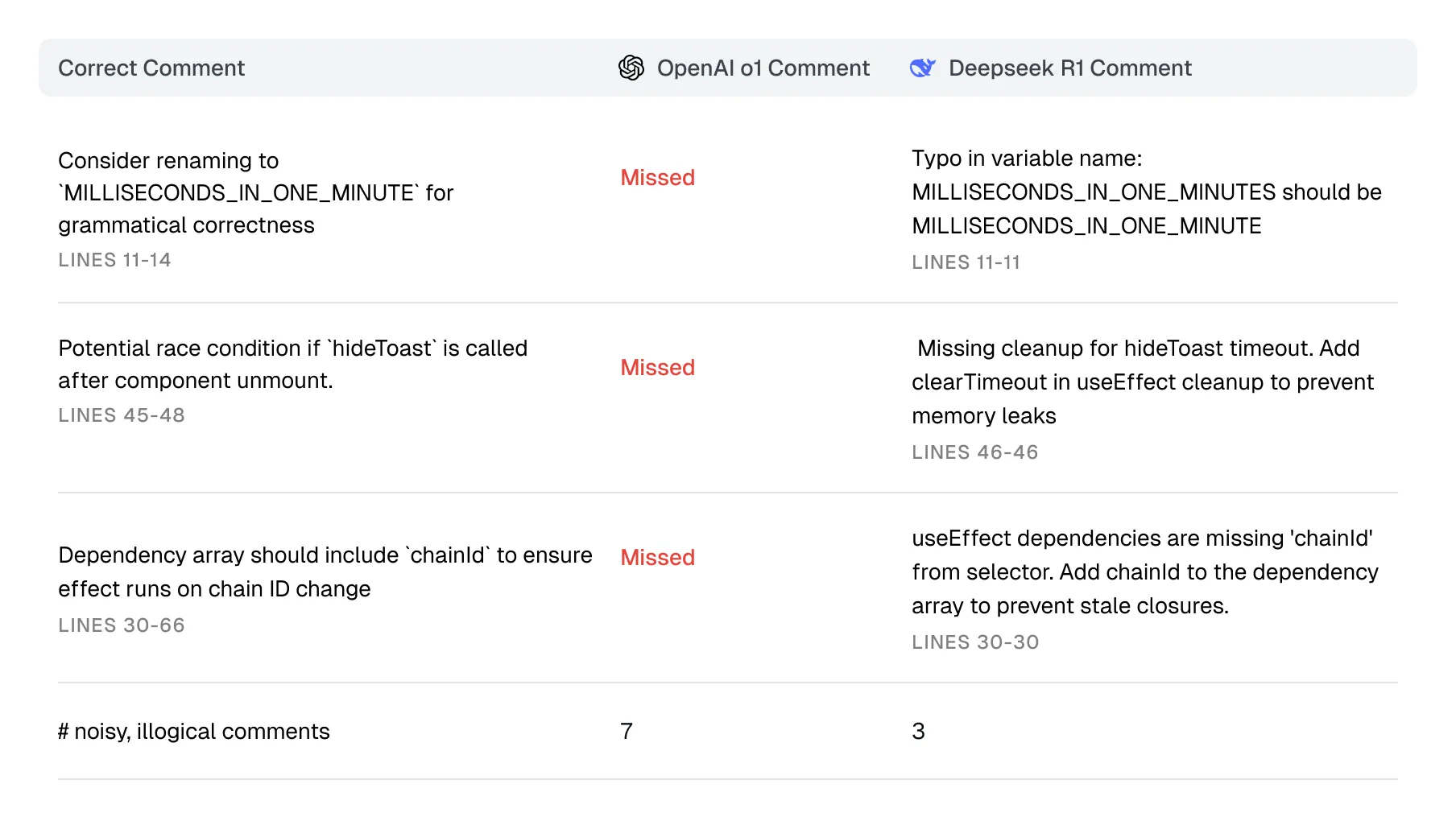
Table showing DeepSeek R1 and OpenAI o1 review results
OpenAI o1 failed to surface any of the issues. The one that surprised me most was the naming issue, which any normal LLM should be able to identify without reasoning.
DeepSeek R1 successfully caught all three!
On the flipside, both produced additional comments that were irrelevant and mostly incorrect, but OpenAI produced more.
Pull Request 2:
This one was a little trickier - four unique issues to surface, one of them occurring twice: a token-related security issue, a missing attribute in a request, opportunity to refactor away method overloading, and a potential runtime error.
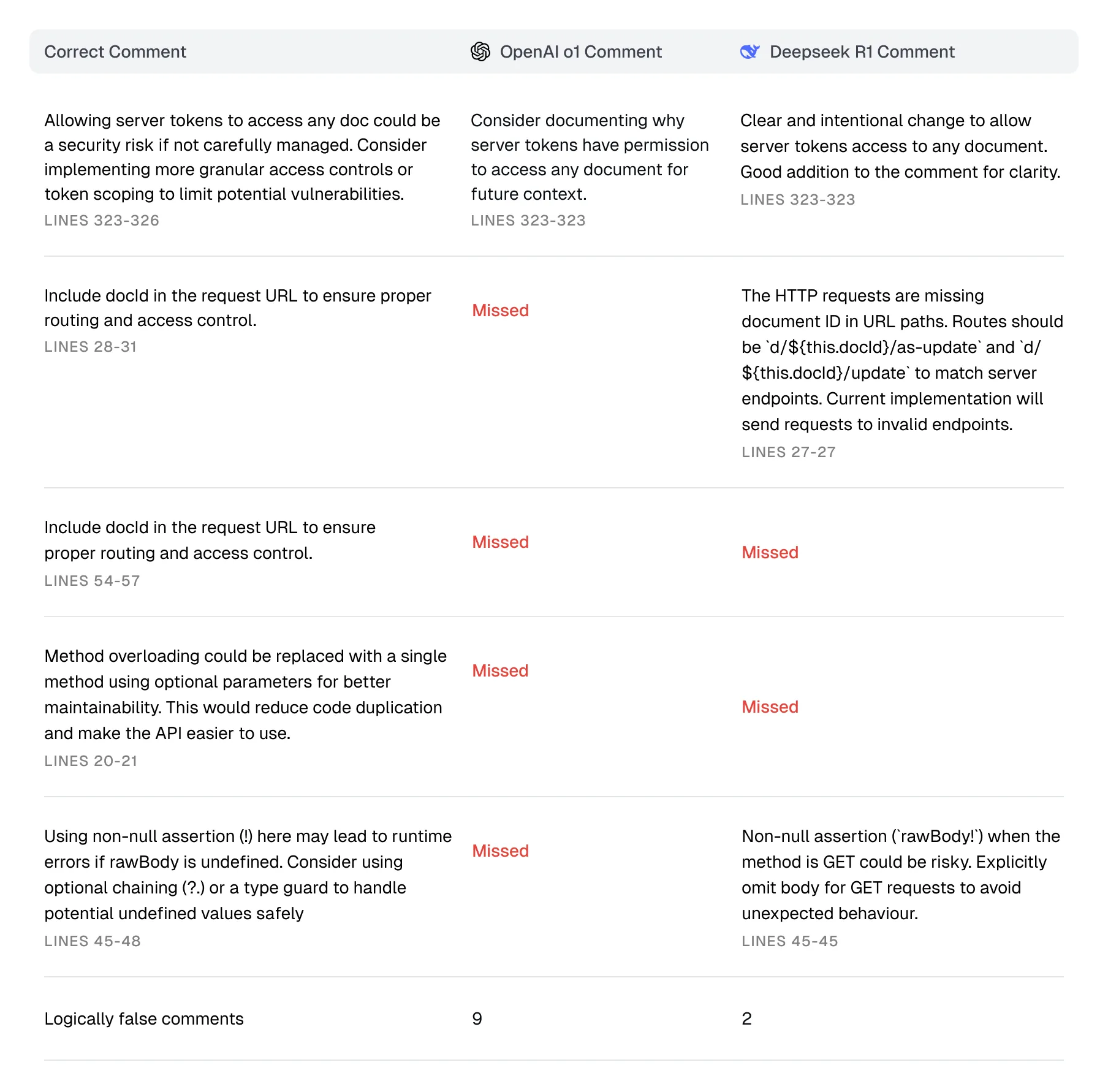
Table showing DeepSeek R1 and OpenAI o1 review results
Both bots picked up on the security issue, although curiously neither considered the issue to be objectively bad, just that it required further explanation.
OpenAI missed the missing attribute, but DeepSeek caught it.
Neither model caught the second occurrence of the missing attribute, and neither pointed out the overload.
Once again, I was surprised that OpenAI did not catch the potential runtime error, which DeepSeek did.
Pull Request 3:
This was the trickiest pull request. Lots of minor issues and not really many obvious ones: some logical issues with an arrow function, a redundant function, use of the incorrect function, a redundant TODO comment, and lastly, a logical issue with a string trim.
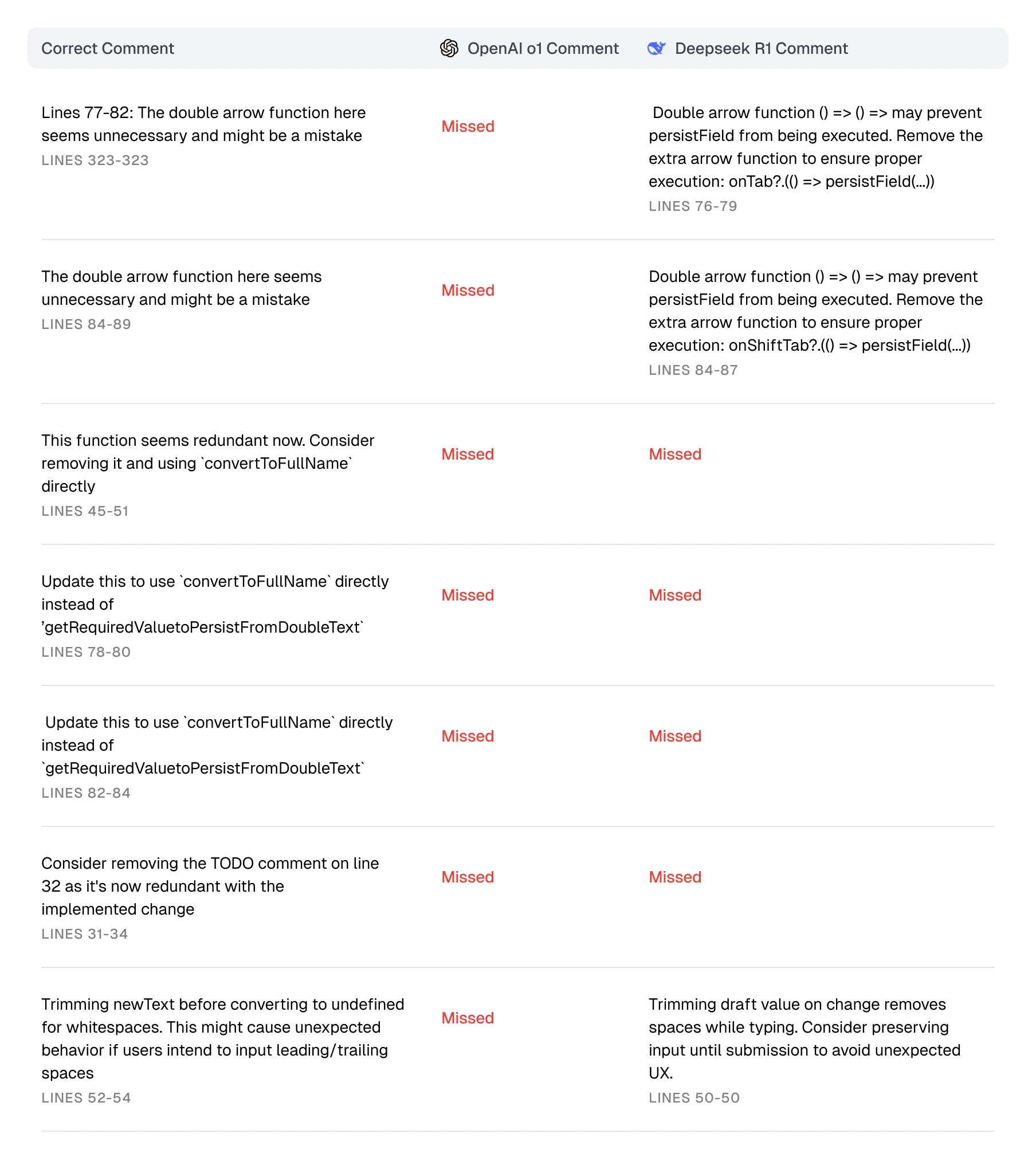
Table showing DeepSeek R1 and OpenAI o1 review results
OpenAI failed to surface any of these issues. DeepSeek R1 caught 3/7, but arguably the most important 3.
Conclusion
Transparently, I was skeptical of DeepSeek’s performance before this test. Until now, open source models have fallen short of their closed source counterparts on both benchmarks and specific real-world applications. It seems that those days may be over, and there may be a world where we can have a true open source model without any performance sacrifices.



